lca
简介
LCA --算法竞赛专题解析(29) - 罗勇军999 - 博客园
Lowest Common Ancestor
LCA 是指在一棵树中,距离两个点最近的两者的公共节点。也就是说,在两个点通往根的道路上,肯定会有公共的节点,我们就是要求找到公共的节点中,深度尽量深的点。还可以表示成另一种说法,就是如果把树看成是一个图,这找到这两个点中的最短距离。
定义
性质
LCA 算法有在线算法也有离线算法,所谓的在线算法就是实时性的,而离线算法则是要求一次性读入所有的请求,然后在统一得处理。而在处理的过程中不一定是按照请求的输入顺序来处理的。说不定后输入的请求在算法的执行过程中是被先处理的。
这里主要是讨论 tarjan 算法|与|倍增算法(待更)与树链剖分(需要学到高级数据结构(待更))的做法,这三种可以解决几乎所有问题。倍增和树链剖分用的尤其多。具体其他做法看 oi. wiki 即可
最近公共祖先 (Lowest Common Ancestor) - 知乎有详细说明
也可以看董晓算法的视频 322 Tarjan算法 P3379【模板】最近公共祖先(LCA)_哔哩哔哩_bilibili
董晓算法很详细的讲了三种方法:倍增,tarjan,树链剖分,甚至更深入的知识。
朴素算法
倍增算法
是在线算法
倍增法的总计算量包括预计算
董晓算法的模板
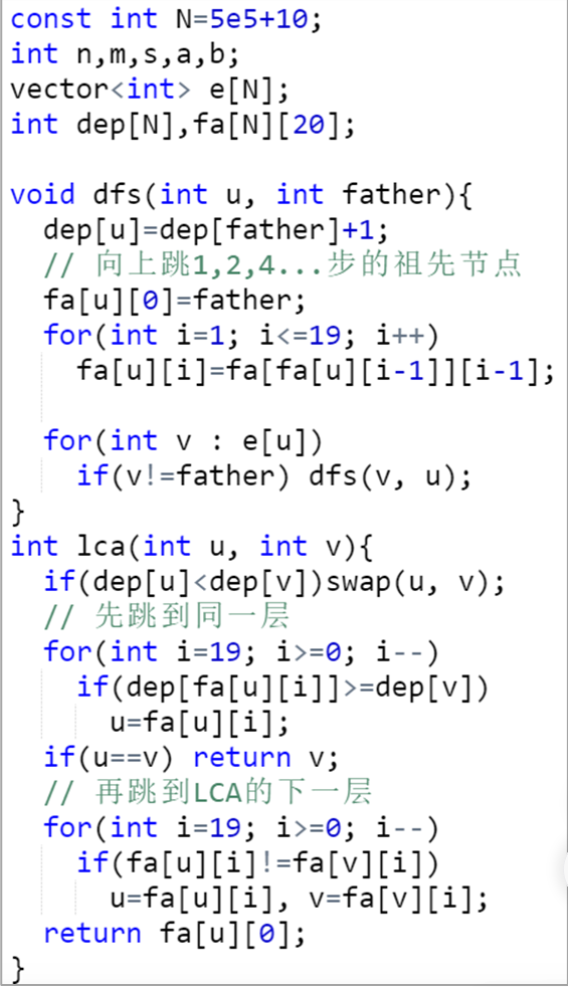
这个模板过洛谷模板题
#include <bits/stdc++.h>
using namespace std;
const int N = 5e5 + 10, M = 2 * N;
int n, m, s, a, b;
int dep[N], fa[N][22];
int h[N], to[M], ne[M], tot;
void add(int a, int b){
to[++tot] = b, ne[tot] = h[a], h[a] = tot;
}
void dfs(int x, int f)
{
dep[x] = dep[f] + 1;
fa[x][0] = f;
for (int i = 0; i <= 20; i++)
fa[x][i + 1] = fa[fa[x][i]][i];
for (int i = h[x]; i; i = ne[i])
if (to[i] != f)
dfs(to[i], x);
}
int lca(int x, int y)
{
if (dep[x] < dep[y])
swap(x, y);
for (int i = 20; ~i; i--)
if (dep[fa[x][i]] >= dep[y])
x = fa[x][i];
if (x == y)
return y;
for (int i = 20; ~i; i--)
if (fa[x][i] != fa[y][i])
x = fa[x][i], y = fa[y][i];
return fa[x][0];
}
int main()
{
ios::sync_with_stdio(false), cin.tie(nullptr);
cin >> n >> m >> s;
for (int i = 1; i < n; i++)
{
cin >> a >> b;
add(a, b);
add(b, a);
}
dfs(s, 0);
while (m--)
{
cin >> a >> b;
cout << lca(a, b) << '\n';
}
}
Tarjan算法
跳转回简介
比较稳定,复杂度较好
是离线算法
过程
Tarjan 算法是一种离线算法,需要使用并查集记录某个结点的祖先结点。做法如下:
- 首先接受输入边 (邻接链表) 、查询边 (存储在另一个邻接链表内) 。查询边其实是虚拟加上去的边,为了方便,每次输入查询边的时候,将这个边及其反向边都加入到 queryEdge 数组里。
- 然后对其进行一次 DFS 遍历,同时使用 visited 数组进行记录某个结点是否被访问过、 parent 记录当前结点的父亲结点。
- 其中涉及到了回溯思想,我们每次遍历到某个结点的时候,认为这个结点的根结点就是它本身。让以这个结点为根节点的 DFS 全部遍历完毕了以后,再将这个结点的根节点设置为这个结点的父一级结点。
- 回溯的时候,如果以该节点为起点,queryEdge 查询边的另一个结点也恰好访问过了,则直接更新查询边的 LCA 结果。
- 最后输出结果。
tarjan性质
Tarjan 算法需要初始化并查集,所以预处理的时间复杂度为
朴素的 Tarjan 算法处理所有
注意
并不存在「朴素 Tarjan LCA 算法中使用的并查集性质比较特殊,单次调用 find ( ) 函数的时间复杂度为均摊
以下的朴素 Tarjan 实现复杂度为
oiwiki 模板
#include<bits/stdc++.h>
using namespace std;
class Edge
{
public:
int toVertex, fromVertex;
int next;
int LCA;
Edge() : toVertex(-1), fromVertex(-1), next(-1), LCA(-1){};
Edge(int u, int v, int n) : fromVertex(u), toVertex(v), next(n), LCA(-1){};
};
const int MAX = 100;
int head[MAX], queryHead[MAX];
Edge edge[MAX], queryEdge[MAX];
int parent[MAX], visited[MAX];
int vertexCount, queryCount;
void init()
{
for (int i = 0; i <= vertexCount; i++)
parent[i] = i;
}
int find(int x)
{
if (parent[x] == x)
return x;
return parent[x] = find(parent[x]);
}
void tarjan(int u)
{
parent[u] = u;
visited[u] = 1;
for (int i = head[u]; i != -1; i = edge[i].next)
{ //[[链式前向星存图]]
Edge &e = edge[i];
if (!visited[e.toVertex])
{
tarjan(e.toVertex);
parent[e.toVertex] = u;
}
}
for (int i = queryHead[u]; i != -1; i = queryEdge[i].next)
{
Edge &e = queryEdge[i];
if (visited[e.toVertex])
{
queryEdge[i ^ 1].LCA = e.LCA = find(e.toVertex);
}
}
}
int main()
{
memset(head, 0xff, sizeof(head));
memset(queryHead, 0xff, sizeof(queryHead));
cin >> vertexCount >> queryCount;
int count = 0;
for (int i = 0; i < vertexCount - 1; i++)
{
int start = 0, end = 0;
cin >> start >> end;
edge[count] = Edge(start, end, head[start]);
head[start] = count;
count++;
edge[count] = Edge(end, start, head[end]);
head[end] = count;
count++;
}
count = 0;
for (int i = 0; i < queryCount; i++)
{
int start = 0, end = 0;
cin >> start >> end;
queryEdge[count] = Edge(start, end, queryHead[start]);
queryHead[start] = count;
count++;
queryEdge[count] = Edge(end, start, queryHead[end]);
queryHead[end] = count;
count++;
}
init();
tarjan(1);
for (int i = 0; i < queryCount; i++)
{
Edge &e = queryEdge[i * 2];
cout << "(" << e.fromVertex << "," << e.toVertex << ") " << e.LCA << endl;
}
}
输入
9 2
1 5
1 4
4 9
5 2
5 6
5 7
6 3
6 8
3 4
7 8
输出
(3,4) 1-----1即为3,4的最近公共祖先
(7,8) 5
董晓算法的模板 (推荐,更易懂)
//预处理
for (int i = 1; i < n;i++)
{
int a, b;
cin >> a >> b;
e[a].push_back(b);
e[b].push_back(a);
}
for (int i = 1; i <= m;i++)
{
int a, b;
cin >> a >> b;
query[a].push_back({b, i});
query[b].push_back({a, i});
}
for (int i = 1; i <= n; i++)
fa[i] = i;
//核心代码
int n, m, r;
vector<int> e[N*2];
vector<pair<int, int>> query[N*2];
int fa[N], vis[N], ans[N];
int find(int u)
{
if(u==fa[u])
return u;
return fa[u] = find(fa[u]);
}
void tarjan(int u)
{
vis[u] = 1;
for(auto v:e[u])
{
if(!vis[v])
{
tarjan(v);
fa[v] = u;
}
}
for(auto q:query[u])
{
int v = q.first, i = q.second;
if(vis[v])
ans[i] = find(v);
}
}
洛谷模板题 (721 ms)
#include <bits/stdc++.h>
using i64 = long long;
inline int read() {
bool sym = false; int res = 0; char ch = getchar();
while (!isdigit(ch)) sym |= (ch == '-'), ch = getchar();
while (isdigit(ch)) res = (res << 3) + (res << 1) + (ch ^ 48), ch = getchar();
return sym ? -res : res;
}
constexpr int N = 5E5 + 10;
int fa[N], head[N], cnt, head_query[N], cnt_query, ans[N];
bool vis[N];
struct Edge {
// 链式前向星
int to, next, num;
} edge[N << 1], query[N << 1];
void addedge(int u, int v) {
// 链式前向星加边
edge[++cnt].to = v;
edge[cnt].next = head[u];
head[u] = cnt;
}
void add_query(int x, int y, int num) {
query[++cnt_query].to = y;
query[cnt_query].num = num;
query[cnt_query].next = head_query[x];
head_query[x] = cnt_query;
}
int find(int x) {
return (fa[x] == x ? x : fa[x] = find(fa[x]));
}
void tarjan(int x) {
vis[x] = true;
for (int i = head[x]; i; i = edge[i].next) {
int y = edge[i].to;
if (!vis[y]) {
tarjan(y);
fa[y] = x;
// 合并并查集
}
}
for (int i = head_query[x]; i; i = query[i].next) {
int y = query[i].to;
if (vis[y]) {
ans[query[i].num] = find(y);
}
}
}
int main() {
std::memset(vis, false, sizeof(vis));
int n = read(), m = read(), root = read();
for (int i = 1; i < n; i++) {
fa[i] = i;
int u = read(), v = read();
addedge(u, v), addedge(v, u);
}
fa[n] = n;
for (int i = 1; i <= m; i++) {
int x = read(), y = read();
add_query(x, y, i);
add_query(y, x, i);
}
tarjan(root);
for (int i = 1; i <= m; i++) {
printf("%d\n", ans[i]);
}
}
董晓算法模板 (3.02 s),加入快读后 (1.75s)换了一种快读后(1.69s)
#include <bits/stdc++.h>
using namespace std;
int n, m, r;
const int N = 500010;
vector<int> e[N];
vector<pair<int, int>> query[N];
int fa[N], vis[N], ans[N];
int find(int u)
{
if(u==fa[u])
return u;
return fa[u] = find(fa[u]);
}
void tarjan(int u)
{
vis[u] = 1;
for(auto v:e[u])
{
if(!vis[v])
{
tarjan(v);
fa[v] = u;
}
}
for(auto q:query[u])
{
int v = q.first, i = q.second;
if(vis[v])
ans[i] = find(v);
}
}
int main()
{
cin >> n >> m >> r;
for (int i = 1; i < n;i++)
{
int a, b;
cin >> a >> b;
e[a].push_back(b);
e[b].push_back(a);
}
for (int i = 1; i <= m;i++)
{
int a, b;
cin >> a >> b;
query[a].push_back({b, i});
query[b].push_back({a, i});
}
for (int i = 1; i <= n; i++)
fa[i] = i;
tarjan(r);
for (int i = 1; i <= m;i++)
cout << ans[i] << "\n";
}
用欧拉序列转化为 RMQ 问题
树链剖分
动态树
标准 RMQ
应用
- 求树上两点之间的距离
- 树上差分
具体参考 oi. wiki
定义
最近公共祖先简称 LCA (Lowest Common Ancestor) 。两个节点的最近公共祖先,就是这两个点的公共祖先里面,离根最远的那个。为了方便,我们记某点集
性质
; 是 的祖先,当且仅当 ; - 如果
不为 的祖先并且 不为 的祖先,那么 分别处于 的两棵不同子树中; - 前序遍历中,
出现在所有 中元素之前,后序遍历中 则出现在所有 中元素之后; - 两点集并的最近公共祖先为两点集分别的最近公共祖先的最近公共祖先,即
- 两点的最近公共祖先必定处在树上两点间的最短路上;
,其中 是树上两点间的距离, 代表某点到树根的距离。