Agent基础#
定义与四要素#
智能体(Agent)是能够通过传感器(Sensors) 感知所处环境(Environment),并自主地通过执行器(Actuators) 采取行动(Action) 以达成特定目标的实体。
| 要素 | 说明 | 示例 |
|---|---|---|
| 环境 | 智能体所处的外部世界 | 道路交通、金融市场、游戏场景 |
| 感知 | 通过传感器持续获取环境状态 | 摄像头、麦克风、雷达、API 接口 |
| 行动 | 通过执行器改变环境状态 | 机械臂动作、代码调用、文本输出 |
| 自主性 | 核心特征,基于感知和内部状态独立决策 | 自主规划路径而非被动响应指令 |
PEAS 任务环境描述模型#
PEAS 是描述 Agent 任务环境的标准化框架,包含四个维度:Performance(性能度量)、Environment(环境)、Actuators(可采取的动作)、Sensors(可感知的信息来源)。
以自动驾驶为例:Performance 是安全抵达、燃油效率、乘客舒适度;Environment 是道路、交通信号、行人、天气;Actuators 是方向盘、油门、刹车、转向灯;Sensors 是摄像头、激光雷达、GPS、惯性测量单元。
六类智能体演进路径#
智能体的分类按决策架构从简单到复杂演进:
-
简单反射智能体(Simple Reflex Agent):基于条件-动作规则直接响应当前感知,不维护内部状态。示例:自动恒温器。
-
基于模型的反射智能体(Model-based Reflex Agent):在反射基础上增加内部世界模型,具备初级记忆,能够处理部分可观测环境。示例:隧道中的自动驾驶汽车。
-
基于目标的智能体(Goal-based Agent):在模型基础上增加了对”目标状态”的显式表示,能够主动选择导向目标的行动。示例:GPS 路径规划系统。
-
基于效用的智能体(Utility-based Agent):在目标基础上增加了效用函数,能够在多个目标间进行权衡和优先级排序,选择最大化期望效用的行动。示例:同时考虑时间、油耗、过路费的导航系统。
-
学习型智能体(Learning Agent):包含学习元素,能够通过与环境交互积累经验,持续改进自身性能。所有学习组件包括:学习元素(改进算法)、执行元素(选择行动)、评判元素(提供反馈)、问题生成器(探索新经验)。示例:AlphaGo Zero。
-
LLM 驱动智能体(LLM-driven Agent):以预训练大语言模型为”大脑”,具备极强的自然语言理解和泛化能力,能够理解模糊指令,结合规划和工具使用完成复杂任务。示例:智能旅行助手。
三类分类维度#
智能体可从三个维度进行分类:
按内部决策架构:简单反射 → 基于模型 → 基于目标 → 基于效用 → 学习型。
按时间与反应性:反应式(毫秒级响应,无规划,如安全气囊、高频交易系统);规划式(深思熟虑后行动,如国际象棋 AI、商业计划系统);混合式(兼顾两者,大多数 LLM Agent 属于此类)。
按知识表示:符号主义(规则 + 逻辑,可解释性强但脆弱);亚符号主义(神经网络,表达能力强但黑箱);神经符号主义(融合两者,LLM Agent 为代表)。
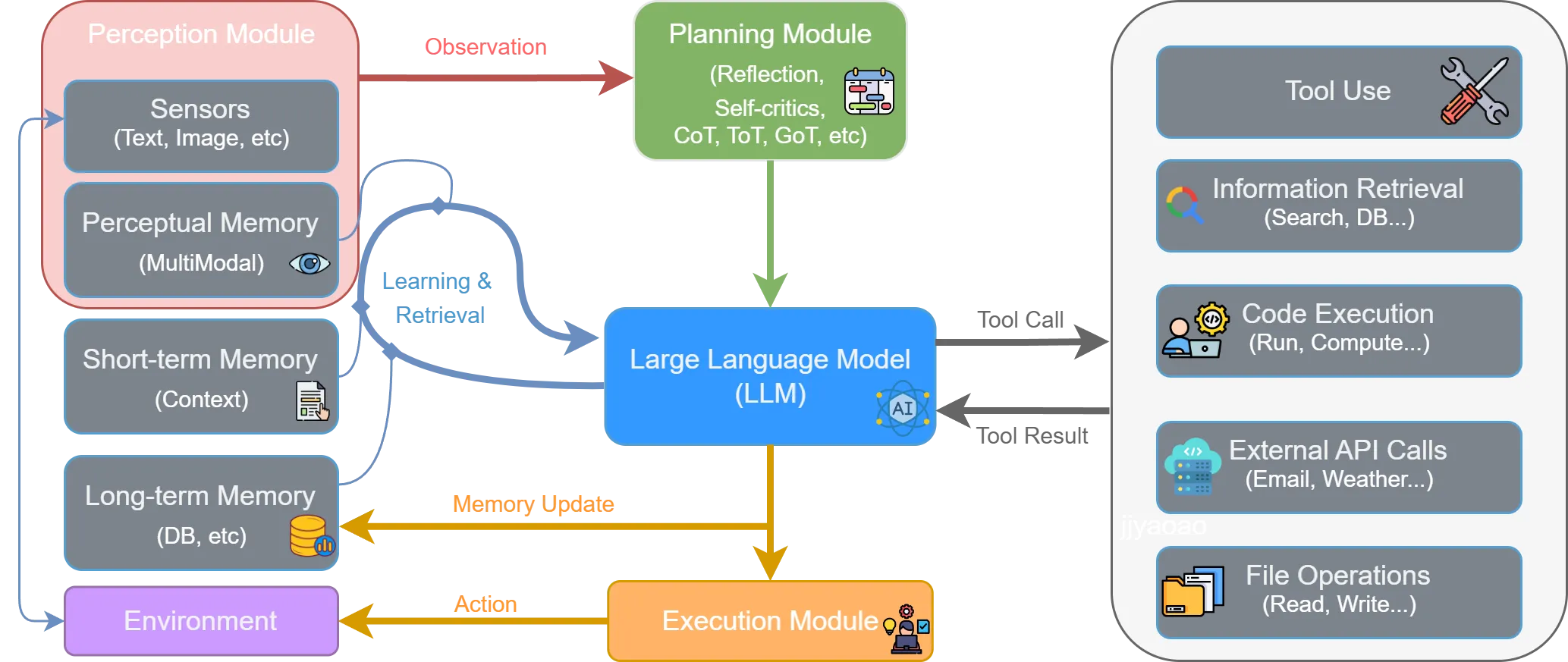
运行机制:感知-思考-行动-观察循环#
智能体的运行遵循一个闭环:
感知(Perception) → 思考(Thought) → 行动(Action) → 观察(Observation) → 循环
├── 规划(Planning)
└── 工具选择(Tool Selection)循环中各环节的含义:
- Thought:内部推理过程的自然语言”快照”,包含对当前状态的分析和下一步计划的推演
- Action:具体操作,以函数调用形式表示,格式为
{工具名}[{工具输入}] - Observation:环境反馈的自然语言描述,作为下一轮推理的输入
普通 LLM 调用与 Agent 的核心差异#
普通 LLM 调用是单轮问答模式,模型收到问题后直接生成回复,缺乏对目标的持续追踪和对外部世界的干预能力。Agent 则是一个持续的控制循环,具备以下三点本质差异:
- Agent 维护明确的目标状态,并能在多轮交互中持续追踪目标
- Agent 具备行动能力,能够通过工具调用影响外部环境并获取反馈
- Agent 能够动态调整计划,在执行过程中根据中间结果修正后续策略
六大核心特征#
LLM 驱动型 Agent 需具备六个核心能力:
- 推理(Reasoning):对问题进行逻辑分析和逐步推导
- 工具使用(Tool Use):识别需要调用外部工具的场景并正确调用
- 记忆(Memory):维护短期上下文和长期知识
- 规划(Planning):将目标分解为可执行的子步骤
- 自我改进(Self-Improvement):通过反馈机制优化自身表现
- 感知(Perception):从环境中获取信息
Agent发展史#
符号主义(1950s–1980s)#
核心理论是纽厄尔与西蒙于 1976 年提出的物理符号系统假说(PSSH):智能的本质 = 符号的表示 + 符号的操作。凡是能通过符号表示和符号操作完成功能的系统,就具备产生智能的必要和充分条件。
代表系统:
- GPS(通用问题求解器,General Problem Solver):通过手段-目的分析(Means-Ends Analysis)将当前状态与目标状态之间的差异转化为可执行的行动。在定理证明和逻辑推理任务中表现良好。
- MYCIN:斯坦福大学开发的医疗诊断专家系统,包含 600 多条由领域专家人工编写的规则,在细菌感染诊断和抗生素推荐方面的准确率超过部分人类医生。
- SHRDLU:Terry Winograd 开发的积木世界智能体,能够在受限的虚拟环境中理解自然语言指令(如”把那块红色的积木放到绿色的上面”)并执行操作。
核心局限:
- 知识获取瓶颈:规则需要领域专家和知识工程师逐条编写,效率极低
- 系统脆弱性:遇到规则边界外的输入时表现急剧下降
- 常识缺失:无法处理人类尽在不言中的常识推理
- 框架问题(Frame Problem):无法有效筛选哪些环境变化与当前目标相关
联结主义(1980s–2010s)#
核心思想是让机器从数据中学习,而非依赖人工编写的规则。关键突破是 1986 年反向传播算法(Backpropagation)的提出,使得多层神经网络的训练成为可能——通过链式法则计算损失函数对每个权重的梯度,从输出层向输入层逐层传播误差信号以更新参数。
代表系统包括 TD-Gammon(使用时序差分学习的强化学习应用,通过自我对弈达到人类专家水平的西洋双陆棋 AI)和 DQN(深度 Q 网络,将深度学习与 Q-Learning 结合,在 Atari 游戏中达到超人类水平)。
联结主义的核心贡献:解决了符号主义面临的知识获取瓶颈(不再需要人工编写规则),通过大规模数据训练自动提取特征和模式。局限在于:模型解释性差、训练需要大量标注数据、容易过拟合。
深度学习(2010s–2022)#
以 AlexNet(2012 年 ImageNet 比赛冠军,引入 ReLU 激活函数和 Dropout 正则化,标志着深度学习时代的开端)、AlphaGo(2016 年击败围棋世界冠军李世石,结合深度神经网络与蒙特卡洛树搜索)、ResNet(2015 年提出残差连接,解决了深层网络的退化问题,使得训练上百层成为可能)为代表。
LLM 驱动时代(2022–至今)#
现代 Agent 采用”感知-思考-行动-观察”闭环,以 GPT 系列模型为大脑。关键节点:
- 2022 年:ReAct 论文提出推理与行动交织的范式;Toolformer 论文提出自监督学习方法让模型学会在文本中插入 API 调用标记
- 2023 年:AutoGPT、BabyAGI 展示自主 Agent 的可行性;Generative Agents 论文展示 Agent 模拟社会行为
- 2024–2025 年:MCP 协议标准化工具接入;Agentic-RL 引入强化学习;多 Agent 协作系统落地
明斯基的”心智社会”理论#
马文·明斯基提出智能来自多样性协作,而非单一完美的推理原则。他认为人类心智由大量相对简单的”智能体”组成,这些智能体按层次组织并相互协作。这一理论为**多智能体系统(MAS)**奠定了理论基础,也解释了为什么多 Agent 协作架构往往能超越单 Agent 的能力上限。
一点点LLM基础#
语言模型演进#
N-gram 模型 → 静态词嵌入(Word2Vec、GloVe)→ 循环神经网络(RNN、LSTM)→ Transformer。
核心转折点是 Transformer 架构通过自注意力机制解决了 RNN 序列处理的两大问题:长距离依赖捕获困难和无法并行计算。
Transformer 核心架构#
自注意力机制(Self-Attention):
每个输入 token 会生成三个向量:Query(查询)、Key(键)、Value(值)。注意力权重的计算过程为:Q 与所有 K 做点积计算相似度 → Softmax 归一化得到权重 → 与 V 加权求和。由此模型在处理每个 token 时,能够动态关注序列中其他所有 token。
多头注意力(Multi-Head Attention):
并行计算多组 Q/K/V 注意力,每组注意力关注不同的语义子空间(语法关系、句法依赖、语义关联等),最后将所有头的输出拼接并线性变换。
位置编码(Positional Encoding):
由于自注意力本身不具备序列的位置信息,需要显式注入位置编码。Transformer 原始论文使用固定频率的正弦余弦函数;现代模型多采用可学习位置编码(如 GPT 系列)或旋转位置编码(RoPE,如 LLaMA 系列)。
前馈网络(FFN):
每个位置的表示经过两层线性变换(中间层进行特征扩展,输出层降回原维度)和非线性激活函数(如 ReLU、GELU)。FFN 在所有位置间共享参数,在注意力机制提取的上下文表示基础上进行更高层次的抽象。
三种架构变体#
- Encoder-Only(BERT):双向注意力,适合文本分类、序列标注、语义匹配等理解类任务。训练目标通常为掩码语言建模(MLM)。
- Decoder-Only(GPT 系列):因果注意力(Causal Attention,每个 token 只能关注自身及之前的 token),适合文本生成类任务。这是当前大语言模型的主流架构选择。
- Encoder-Decoder(T5):编码器做双向理解 + 解码器做自回归生成,适合序列到序列的转换任务(翻译、摘要)。
分词(Tokenization)#
主流分词算法:
- BPE(Byte Pair Encoding):GPT 系列使用。从字符级开始,迭代合并最高频的相邻 token 对。不需要特殊标记或词表预定义,自动学习子词切分。
- WordPiece:BERT 使用。与 BPE 类似,但合并标准为互信息最大化(选择能最大程度提升数据似然的 pair),而非单纯的高频合并。
- SentencePiece:T5、LLaMA 使用。将原始文本直接视为 Unicode 字符序列,不依赖空格分割,天然支持多语言。原始模型训练中使用的是 BPE 的变体(Unigram LM)。
- Tiktoken:OpenAI 开发的高性能分词库,使用 BPE 算法,针对 GPT 系列模型优化,分词速度比 HuggingFace tokenizer 快数倍。
分词的粒度直接影响模型的有效上下文长度和跨语言能力。
采样参数#
控制 LLM 输出随机性的三个核心参数:
-
Temperature:控制概率分布的”尖锐”程度。值趋近于 0 时,最高概率 token 几乎被确定选中,输出确定性强但缺乏多样性。值较高时概率分布更平坦,低概率 token 也有机会被选中,输出更多样。通常在 0.7–0.9 用于创意任务,0.1–0.3 用于精确推理任务。
-
Top-k:解码时仅从概率最高的 k 个 token 中采样,将其余 token 的概率置为零后再归一化。避免了概率分布的”长尾”被小概率 token 污染。
-
Top-p(核采样):设置累积概率阈值 p(如 0.9),仅保留使得累积概率首次超过 p 的最小 token 集合。与 Top-k 的固定数量不同,Top-p 根据当前概率分布动态调整候选集大小。
实际应用中常将 Top-k 和 Top-p 组合使用:先保留 Top-k 个 token,再从其中应用 Top-p 过滤。
上下文学习(In-Context Learning)机制#
ICL 是 LLM 最关键的涌现能力之一:仅通过 prompt 中放置的输入-输出示例,模型就能推断出任务模式并正确泛化,整个过程不涉及任何参数更新。
与微调的本质区别:SFT 通过梯度更新改变模型参数,是一种”学习”;ICL 不修改模型参数,仅利用模型在预训练阶段已经习得的模式匹配能力。ICL 的效果依赖模型规模——小模型(<1B 参数)几乎不具备 ICL 能力,随着模型规模增大 ICL 能力涌现。
ICL 的工作机制解释:一种主流假说是”任务归纳”——prompt 中的示例序列激活了模型预训练阶段见过的类似模式,模型通过注意力机制定位这些模式并延续到最终输出。示例在 prompt 中扮演了”任务格式指示器”的角色,而非”新知识注入”。
在 Agent 中的使用方式:ICL 在 Agent 系统中用于两种场景——系统级静态示例(在系统提示词中放置固定数量、固定格式的工具调用示例,确保 Agent 始终按标准格式输出)和运行时动态示例(根据当前上下文动态选择最相关的示例加入 prompt,通常在 RAG 场景中使用)。
提示工程(Prompt Engineering)#
零样本提示(Zero-shot):直接给出任务描述,模型凭借训练阶段学习的泛化能力执行。适用于大模型(>100B 参数)已具备足够能力的常见任务。
少样本提示(Few-shot):在 prompt 中给出若干输入-输出示例,模型通过上下文学习(In-Context Learning)推断任务模式。示例数量通常在 3–10 个,过多示例可能超出上下文窗口限制。
思维链(Chain-of-Thought, CoT):在 prompt 中加入中间推理步骤的示例,引导模型在输出最终答案前先生成逐步推理过程。显著提升需要多步逻辑推导的任务(数学题、逻辑推理、常识推理)的准确率。可分为人工编写 CoT 示例和零样本 CoT(仅添加”Let’s think step by step”等触发词)。
思维树(Tree of Thoughts, ToT):将推理过程扩展为树状搜索结构。每个节点表示一种推理状态或中间结论,从根节点出发探索多条推理路径,通过 LLM 自身对每条路径进行评估打分,采用广度优先搜索(BFS)或深度优先搜索(DFS)选择最优路径。适合需要探索多种可能性、存在多条可行解题路径的复杂问题。
自洽性(Self-Consistency):对同一问题多次采样(使用略高的 Temperature),然后通过多数投票或加权投票选择出现频率最高的答案。利用了 LLM 每次生成结果的随机性——虽然单次可能出错,但多次采样的共识倾向于正确。
训练范式#
LLM 的训练分为三个阶段:
-
预训练(Pre-training):在海量无标注文本(通常数 TB)上训练下一个 token 预测任务。此阶段模型关注文本中 token 的共现和序列模式,学到语言知识、世界知识和推理能力的基础。所需计算资源巨大(数千 GPU 小时)。
-
指令微调(Instruction Fine-tuning, SFT):在人工标注或合成生成的指令-回复数据上继续训练。数据格式为
{指令, 输入, 期望输出}三元组。具体示例:
{
"instruction": "计算 25 和 37 的和",
"input": "",
"output": "25 + 37 = 62"
}
{
"instruction": "写一个 Python 函数计算斐波那契数列",
"input": "n = 10",
"output": "def fibonacci(n):\n if n <= 1:\n return n\n return fibonacci(n-1) + fibonacci(n-2)\n\nprint(fibonacci(10))"
}此阶段教会模型遵循指令和格式化回复,使其从”能补全文本”变为”能回答问题”。
- 人类反馈强化学习(RLHF):分为三个子步骤——收集人类偏好数据(对同一 prompt 的多个模型输出排序)→ 训练奖励模型(Reward Model,学会预测人类偏好)→ 用 PPO 算法优化策略模型(使模型输出最大化奖励模型评分)。RLHF 使模型输出在语言质量、事实性、安全性上更符合人类期望。
LoRA(Low-Rank Adaptation)是一种参数高效的微调方法。对于预训练权重矩阵 W,LoRA 将其更新量 ΔW 分解为两个低秩矩阵 A 和 B 的乘积(ΔW = B·A),训练时只更新 A 和 B 的参数,冻结原始权重。训练完成后将低秩矩阵合并回原权重,推理时无额外延迟。以 Qwen3-0.6B 为例,使用 LoRA 微调仅需约 4GB 显存。
Scaling Laws 与涌现能力#
Scaling Laws(缩放法则)揭示了模型性能与三个因素之间的幂律关系:模型参数量(N)、训练数据量(D)、计算资源量(C)。当三者在对数尺度上等比例增加时,模型性能按幂律持续提升,没有明显的收益递减拐点。
当模型规模跨越某个阈值时,会涌现出小模型不具备的能力:
- 上下文学习(In-Context Learning):仅通过 prompt 中的示例就能理解任务,无需梯度更新
- 思维链推理:能够执行多步逻辑推理
- 指令遵循:理解并以自然语言描述的执行指令
- 工具调用:识别需要外部工具的场景并生成结构化参数
幻觉问题#
幻觉指模型生成与事实不符的内容。分为三类:
- 事实性幻觉:生成与已知事实矛盾的内容(如将”北京是中国的首都”写成”上海是中国的首都”)
- 忠实性幻觉:生成与用户指令或对话历史不一致的内容(如用户说”我叫张三”,模型回复”李四你好”)
- 内在幻觉:生成与模型自身训练数据中的知识相矛盾的内容
缓解方案:RAG(检索相关文档作为生成依据)、外部工具验证(调用搜索引擎或数据库核实事实)、多模型投票(多个模型独立判断事实性)、幻觉检测提示(在 prompt 中加入”如果你的回答中包含不确信的信息,请标注出来”)。
Toolformer:让模型学会调用工具#
Toolformer 是 Meta AI 于 2023 年提出的方法,核心思想是不修改模型架构,而是通过自监督学习方式让语言模型学会在适当的时机调用外部工具(计算器、搜索引擎、翻译系统等)。
API 调用表示:在文本序列中使用特殊 token 标记 API 调用的开始和结束:<API> a_c(i_c) </API>(无结果状态)和 <API> a_c(i_c) → r </API>(有结果状态)。通过这种设计,API 调用可以无缝地插入到文本生成过程中。
训练数据构建采用”采样-执行-过滤”三阶段:
- 采样阶段:使用少量人工编写的少样本示例引导模型在文本中找到可能需要的工具调用位置,对每个位置生成
<API>token 的概率,保留概率高于阈值的位置 - 执行阶段:实际调用对应的 API,获取真实的返回结果
- 过滤阶段:比较使用 API 调用和不使用 API 调用两种情况下的加权交叉熵损失。仅当 API 调用能显著降低损失时才保留该样本
推理过程:模型正常解码。当输出 → token 时系统暂停执行 API 调用,将结果插入文本后继续解码。
实验效果:Toolformer(6.7B 参数)在零样本任务上超越了 GPT-3(175B 参数),且微调后未牺牲语言模型的原生能力——事实完成任务准确率从 39.8% 提升至 53.5%,数学任务准确率从 14.0% 提升至 40.4%。
局限:仅支持单次非迭代调用(无法形成工具链)、无成本感知(不考虑 API 延迟和费用)、API 集合固定(扩展新工具需重新训练)、对提示词敏感。
Agent经典范式#
ReAct#
ReAct(Reasoning + Acting)由 Shunyu Yao 于 2022 年提出,是目前最广泛使用的 Agent 范式。其核心思想是将推理(Reasoning)与行动(Acting)紧密结合,形成**思考(Thought)→ 行动(Action)→ 观察(Observation)**的闭环。
循环结构#
整个执行过程是一个 while 循环,每次迭代包含六个步骤:
- 格式化 Prompt:将系统指令、可用工具描述、当前问题、历史交互记录组装成当前轮次的 prompt
- 调用 LLM:将 prompt 发送给 LLM 获取回复
- 解析输出:从 LLM 回复中提取 Thought 和 Action 字段
- 判断终止条件:如果 Action 为
Finish[最终答案],则输出结果并结束循环 - 执行工具:如果 Action 为
{工具名}[{工具输入}],调用对应工具获取 Observation - 更新历史:将 Action 和 Observation 追加到历史记录中,回到步骤 1 继续
系统 Prompt 模板#
请注意,你是一个有能力调用外部工具的智能助手。
可用工具如下:
{tools}
请严格按照以下格式进行回应:
Thought: [你的思考过程,用于分析问题、拆解任务和规划下一步行动]
Action: 你决定采取的行动,必须是以下格式之一:
- `{tool_name}[{tool_input}]`: 调用一个可用工具。
- `Finish[最终答案]`: 当你认为已经获得最终答案时。
现在,请开始解决以下问题:
Question: {question}
History: {history}核心代码实现#
class ReActAgent:
def __init__(self, llm_client, tool_executor, max_steps=5):
self.llm_client = llm_client
self.tool_executor = tool_executor
self.max_steps = max_steps
self.history = []
def _parse_output(self, text):
"""从 LLM 回复中提取 Thought 和 Action"""
thought_match = re.search(r"Thought: (.*?)Action:", text, re.DOTALL)
action_match = re.search(r"Action: (.*)", text, re.DOTALL)
thought = thought_match.group(1).strip() if thought_match else None
action = action_match.group(1).strip() if action_match else None
return thought, action
def _parse_action(self, action_text):
"""解析 Action 字符串,分离工具名和参数"""
match = re.match(r"(\w+)\[(.*)\]", action_text)
if match:
return match.group(1), match.group(2)
return None, None
def run(self, question):
self.history = []
for current_step in range(self.max_steps):
tools_desc = self.tool_executor.get_available_tools()
history_str = "\n".join(self.history)
prompt = REACT_PROMPT_TEMPLATE.format(
tools=tools_desc, question=question, history=history_str,
)
messages = [{"role": "user", "content": prompt}]
response_text = self.llm_client.think(messages=messages)
thought, action = self._parse_output(response_text)
if action.startswith("Finish"):
final_answer = re.match(r"Finish\[(.*)\]", action).group(1)
return final_answer
tool_name, tool_input = self._parse_action(action)
observation = self.tool_executor.execute(tool_name, tool_input)
self.history.append(f"Action: {action}")
self.history.append(f"Observation: {observation}")
return None运行示例#
以查询”华为最新手机”为例:
--- 第 1 步 ---
Thought: 我需要查找华为最新发布的手机型号,使用搜索工具。
Action: Search[华为最新手机型号及主要卖点]
Observation: [结果列表:HUAWEI Pura 70 系列...Mate 60 Pro...]
--- 第 2 步 ---
Thought: 根据搜索结果,Pura 70 是最新发布的,我总结一下卖点。
Action: Finish[华为最新旗舰是 HUAWEI Pura 70 系列,卖点包括...]优缺点#
优势:高可解释性(Thought 链可完整追溯决策过程)、动态规划(每步可根据上一步的结果调整策略)、工具协同(LLM 负责规划,工具负责执行)。
缺陷:强依赖模型能力(LLM 推理弱则效果差)、执行效率低(串行循环需要多次 LLM 调用)、Prompt 脆弱(格式或标点变化可能导致解析失败)、可能陷入局部最优或推理死循环。
Plan-and-Solve#
Plan-and-Solve 在 ReAct 的基础上增加了明确的全局规划阶段。Agent 首先制定一个完整的执行计划,再逐步执行,执行过程中可根据实际情况调整计划。
架构:由两个组件协作完成——规划器(Planner)将复杂任务拆解为一系列逻辑清晰的子步骤(输出为结构化的步骤列表),执行器(Executor)严格按照步骤逐一落实,每一步将原始问题、完整计划、历史结果作为上下文传给模型。
核心 Prompt 模板:
你是一个"先规划后执行"的智能体。
可用工具如下:
{tools}
请先分析问题,生成一个完整的执行计划(步骤列表),然后严格按照计划执行。
问题:{question}
请先输出计划(Plan),然后按步骤执行(Execute)。实际实现中,规划器和执行器的 Prompt 是分开设计的:规划器 Prompt 要求模型输出结构化的步骤列表;执行器 Prompt 传入原始问题 + 完整计划 + 已执行步骤的结果,要求模型按计划继续执行。
与 ReAct 的区别:ReAct 适合”边走边看”的探索性任务,每一步的推理依托上一步的观察结果。Plan-and-Solve 适合逻辑路径相对明确的多步任务,如编写一段代码(先规划文件结构再逐个实现)。前者灵活但可能缺乏方向,后者稳定但缺乏灵活性。
Reflection(自我反思)#
Reflection 范式赋予 Agent 评估自身输出并修正的能力。论文《Self-refine: Iterative refinement with self-feedback》证明:在所有任务、所有测试模型(GPT-3.5、GPT-4、Claude)上,反思模式全面碾压直接生成。
流程与 Prompt 模板#
流程包含三个阶段,每个阶段对应独立的 Prompt 模板:
- 生成阶段(Execution):Agent 针对任务生成初始回答
请完成以下任务:
任务:{task}
请直接输出最终结果,不要包含任何多余的开头或结尾解释。- 评估阶段(Reflection):Agent 对自己的回答进行评判,寻找事实错误、逻辑漏洞或不一致之处
你是一位极其严格的评审专家。请审查以下内容的质量、准确性和逻辑性。
任务:{task}
当前内容:
{content}
请指出不足之处并提供具体的改进建议。如果内容已经非常完美,达到了最高标准,请严格且仅输出"无需改进"四个字。- 改进阶段(Refinement):基于评估结果生成改进版本,可多次迭代
请根据评审专家的反馈,优化你之前生成的内容。
任务:{task}
评审员的反馈:
{feedback}
请直接输出优化后的完整最新内容,不要包含任何额外的解释。Producer-Critic 模式#
Producer(生成者)和 Critic(评审者)使用不同的系统提示词,职责分离避免了”自己写自己审”的认知偏见。实际实现中可以使用不同的模型(如生成用快速模型、反思用更强模型)。
停止条件#
反思循环的停止条件包括:Critic 认为输出已达标(返回”无需改进”信号);达到最大迭代次数(通常 2–3 轮);改进幅度小于设定阈值。
适用的自我检查维度#
| 检查类型 | 检查内容 |
|---|---|
| 结构自检 | 输出格式是否完整?是否包含所有必须字段? |
| 事实自检 | 是否包含不可验证的事实?是否可能误导用户? |
| 工具行为自检 | 工具调用是否成功?错误信息是否为空? |
| 推理逻辑自检 | 是否存在逻辑跳跃?关键步骤缺失?未说明的假设? |
Reflection 的核心价值:在没有外部反馈时,让 Agent 利用模型自身对”正确”和”错误”的判断能力进行自我修正。在代码生成(检查语法错误和逻辑 bug)、数学推理(检查计算过程)等输出可以自我验证的任务中效果显著。
Tree of Thoughts(ToT)#
ToT 将推理过程建模为树状搜索结构,每个节点表示一种推理状态(一段思考或中间结论),从根节点(原始问题)出发探索多条可能的推理路径。
评估与搜索:每个中间节点由 LLM 自身进行评估打分(“这条推理路径是否可行”),然后根据搜索策略决定下一步探索哪些路径。这种方法结合了传统搜索算法与 LLM 的语义评估能力。
两种搜索策略:广度优先搜索(BFS)按层级逐层扩展,每层保留评分最高的 k 个节点,适合分支较浅但宽度大的问题。深度优先搜索(DFS)沿一条路径深入直到达到叶节点(最终答案或死路),然后回溯到上一个分支点继续探索,适合分支较深但宽度窄的问题。
适用场景:需要探索多种可能性、中间结果可以独立评估的任务,如填字游戏、创意写作、数学证明路径选择。以一个填字游戏为例:每个空格节点可以填入多个候选词,LLM 评估每个候选词的合理性和与已有答案的匹配度,BFS 保留最优的几条候选路径继续探索。
ToT 的代价:每次推理需要多次 LLM 调用(每个节点都需要评估),计算成本显著高于 CoT。因此只在问题复杂度高到简单 CoT 无法解决时才值得使用。
Agent 开发框架#
AutoGen(微软)#
基于多 Agent 对话的协作框架,采用对话与消息驱动的协作方式。Agent 之间的核心交互是消息传递——一个 Agent 发送消息,其他 Agent 接收并回复,消息在 Agent 之间流转驱动任务推进。
核心组件:
AssistantAgent:封装 LLM 的助手 Agent,负责生成回复、规划任务UserProxyAgent:代表人类用户的代理 Agent,可以执行代码、调用工具,并将执行结果反馈回对话RoundRobinGroupChat:轮询群聊机制,按固定顺序依次让每个 Agent 发言TextMentionTermination("TERMINATE"):当对话中出现 TERMINATE 关键词时自动结束
实战案例:用 Streamlit 构建比特币价格 Web 应用。角色链为产品经理(定义需求)→ 工程师(编写 Streamlit 代码)→ 代码审查员(审查代码质量)→ 用户代理(实际执行代码并验证结果)。每个 Agent 专注于自己的角色职责,通过群聊对话迭代完善。
AgentScope#
消息驱动的多智能体平台,强调工程化优先的设计哲学:组合式架构 + 消息驱动,适合生产级多 Agent 系统构建。
核心组件:
Msg:统一消息格式,所有 Agent 间通信都封装为标准化的消息对象MsgHub:消息路由中心,支持消息广播、组播、私密频道AgentBase:Agent 基类,核心方法为reply(),子类通过重写该方法定义自己的响应逻辑
实战案例:三国狼人杀游戏。狼人夜通过 MsgHub 建立私密频道(仅狼人 Agent 能通信);使用 Pydantic 结构化输出约束 Agent 行为(确保每个 Agent 在投票、发言时输出格式稳定);设计了容错机制(单个 Agent 异常不中断整个游戏流程,由 MsgHub 管理异常 Agent 的消息分发)。
CAMEL#
设计哲学为”轻架构、重提示”——通过巧妙地设计 prompt(角色分工 + Inception Prompting),让简单的双 Agent 结构完成复杂任务,无需复杂的工程框架。
核心模式:
- AI User:提需求的角色,向 AI Assistant 下达任务指令
- AI Assistant:执行产出的角色,完成任务并返回结果
- Inception Prompting:在 prompt 中为每个角色注入详细的角色设定(你是谁、你有什么技能、你如何协作),让 Agent 在角色框架内自主协商任务分工
终止标志:<CAMEL_TASK_DONE>,当 AI Assistant 认为任务完成时输出该标记。
实战案例:“心理学家”与”作家”双角色协作创作拖延症科普电子书。AI User(角色:心理学家)定义每章主题和核心论点,AI Assistant(角色:科普作家)撰写章节内容,通过多轮对话逐步完成全书。
LangGraph#
将 Agent 执行流建模为有向图 / 状态机。天然支持循环(ReAct 的 thought-action-observation 循环)、条件分支(根据评估结果走不同路径)、回退(失败后回退到上一步)和 Reflection(自环实现自我评估和改进)。
三要素:
- State(状态):使用
TypedDict定义共享状态,所有 Node 共享并读写 - Node(节点):函数,接收当前 State,返回 State 的部分更新
- Edge(边):普通边(固定路径)和条件边(根据 State 的内容动态决定下一步)
实战案例:三步问答助手。Understand(理解问题意图)→ Search(调用 Tavily 搜索引擎检索信息)→ Answer(整合信息生成回答)。任意一步失败则沿条件边回退到前一步(如 Search 失败就回到 Understand 阶段重新理解问题)。
涌现式协作 vs 显式控制#
| 维度 | 涌现式(AutoGen / CAMEL) | 显式控制(LangGraph) |
|---|---|---|
| 控制权 | 去中心化,Agent 自主协商 | 中心化,开发者预定义流程 |
| 灵活性 | 高,适应动态变化 | 低,流程相对固定 |
| 可靠性 | 低,易主题漂移或死循环 | 高,严格按流程执行 |
| 可审计性 | 差,行为路径不可预期 | 好,执行路径可完全追踪 |
| 适用场景 | 发散型(创意写作、代码生成) | 收敛型(企业自动化、金融核保) |
两个流派并非互斥。实际系统往往混合使用:外层用 LangGraph 定义稳定的大流程,内层用 AutoGen 或 CAMEL 管理发散的子任务。
记忆与检索#
两大痛点#
LLM 无状态:每次 API 调用都是独立计算,模型不会自动”记住”之前的对话内容。这导致四个问题——上下文丢失(多轮对话中重要信息被遗忘)、个性化缺失(模型无法记住用户偏好)、学习能力受限(Agent 不能在每次交互中积累经验)、一致性问题(同一用户的后续请求被视为完全新的对话)。
模型知识有限:训练数据有截止日期,模型不了解事实发生在数据截止之后的事件。训练数据以通用互联网语料为主,专业领域知识覆盖不足。模型在不确定时倾向于”编造”而非”承认不知道”(幻觉)。
记忆系统架构#
HelloAgents 记忆系统
├── 基础设施层
│ ├── MemoryManager(统一调度入口)
│ ├── MemoryItem(通用记忆数据单元)
│ ├── MemoryConfig(每种记忆类型的独立配置)
│ └── BaseMemory(记忆类型的抽象基类)
├── 记忆类型层
│ ├── WorkingMemory(工作记忆)
│ ├── EpisodicMemory(情景记忆)
│ ├── SemanticMemory(语义记忆)
│ └── PerceptualMemory(感知记忆)
├── 存储后端层
│ ├── QdrantVectorStore(向量数据库,高性能语义检索)
│ ├── Neo4jGraphStore(图数据库,知识图谱关系管理)
│ └── SQLiteDocumentStore(结构化持久化存储)
└── 嵌入服务层
├── DashScopeEmbedding(云端 API)
├── LocalTransformerEmbedding(离线部署)
└── TFIDFEmbedding(轻量级兜底方案)嵌入模型选型#
嵌入模型(Embedding Model)负责将文本转化为向量,是记忆系统中所有语义检索的基础。选择嵌入模型需考虑以下维度:
| 维度 | 选项 | 权衡 |
|---|---|---|
| 部署方式 | 云端 API vs 本地部署 | 云端方便但产生额外成本和延迟;本地隐私好但需 GPU 资源 |
| 向量维度 | 384d(MiniLM)vs 768d(BGE)vs 1536d(OpenAI) | 维度越高表达力越强,但存储和检索成本越高 |
| 语言覆盖 | 通用英文 vs 多语言 vs 中文专用 | 中文场景下 BAAI/bge-large-zh-v1.5 优于通用英文模型 |
| 检索精度 | MTEB 基准分数 | BEIR / MTEB 排行榜可作为参考依据 |
| 输入长度 | 512 tokens vs 8192 tokens | 短模型适合句子级检索,长模型适合段落级检索 |
项目中实现三种嵌入方案构成降级链路:DashScopeEmbedding(阿里云通义千问的云端 API,精度最高)→ LocalTransformerEmbedding(使用 Sentence-Transformers 库本地运行,需 GPU)→ TFIDFEmbedding(基于 TF-IDF 的零依赖兜底方案,精度最低但无需任何外部依赖和 GPU)。在 DashScope 不可用时自动降级到 LocalTransformer,再降级到 TFIDF。
向量数据库选型#
项目中默认使用 Qdrant。在实际生产中选择向量数据库时,可参考以下对比:
| 维度 | Chroma | Qdrant | Milvus |
|---|---|---|---|
| 架构类型 | 嵌入式(单进程) | 独立服务 / 云部署 | 分布式集群 |
| 部署复杂度 | 低(pip install) | 中(Docker 单节点) | 高(K8s + etcd + MinIO) |
| 适用规模 | < 10 万条 | 10 万–1000 万条 | > 100 万条 |
| 查询延迟 | 5–20ms | 1–5ms | 2–10ms |
| 混合搜索 | 基础 | 复杂过滤最强 | 完善 |
| 运维成本 | 零配置 | 中等 | 高 |
选型建议:原型阶段可用 Chroma 快速验证 RAG;中等规模(10 万–100 万条)生产环境选 Qdrant;大规模(百万级以上)高并发场景选 Milvus 集群。
四大记忆类型#
| 类型 | 类比 | 存储方式 | 检索重点 | 典型场景 |
|---|---|---|---|---|
| 工作记忆 | 便签纸 / 短期记忆 | 纯内存,TTL 管理,容量限制 | 快速访问、时间衰减、混合检索 | 当前会话的上下文、用户刚刚提及的信息 |
| 情景记忆 | 日记本 | SQLite + Qdrant | 语义相似 + 时间近因性 + 会话过滤 | 发生过的事件、学过的知识、做过的操作 |
| 语义记忆 | 知识百科 | Qdrant + Neo4j | 向量语义 + 图关系推理 | 抽象概念、概念间的关系、用户的长期偏好 |
| 感知记忆 | 感官输入缓存 | 分模态向量集合 | 同模态或跨模态检索 | 图片视觉特征、音频声学特征的暂存和匹配 |
评分机制#
不同类型记忆的检索评分公式各有侧重,突出各自的特化方向:
情景记忆:score = (向量相似度 × 0.8 + 时间近因性 × 0.2) × (0.8 + importance × 0.4)
- 向量相似度权重高:因为情景记忆的核心是回忆”类似的事件”
- 时间近因性权重较低但不可忽略:较新的事件通常有更高的参考价值
- importance 参数调节:重要性评分(0–1),用户可以手动指定或系统自动推算
语义记忆:score = (向量相似度 × 0.7 + 图相似度 × 0.3) × (0.8 + importance × 0.4)
- 向量相似度仍然主导但比例略低:因为语义不仅靠向量匹配
- 图相似度权重 0.3:通过 Neo4j 中的知识图谱关系(如 A”属于”B、C”影响”D)来衡量概念之间的关联度
- 如果 Neo4j 不可用(未配置图数据库),图相似度回退为 0,分数退化为
向量相似度 × (0.8 + importance × 0.4)
工作记忆:final_score = base_relevance × 时间衰减 × (0.8 + importance × 0.4)
- 时间衰减函数:刚写入的工作记忆分数 > 较旧的(TTL 趋近到期时分数趋近于 0)
- 工作记忆不依赖向量检索,因为它的容量有上限(默认 N 条),直接线性遍历即可
MemoryTool 核心操作#
记忆系统通过 MemoryTool 对外暴露统一接口,支持以下操作:
- add:添加记忆条目,指定类型(working / episodic / semantic / perceptual)和重要性评分 importance(0–1)
- search:搜索记忆,支持按类型过滤(搜索一种或多种类型的记忆)、按最小重要性阈值筛选
- forget:遗忘,支持基于重要性策略(遗忘最低重要性的条目)、基于时间策略(遗忘最早的条目)、基于容量策略(当条目数超过上限时自动清理最不重要的)
- consolidate:整合,将短期记忆的重要信息提取并转换为长期记忆。整合算法流程为:从 WorkingMemory 中筛选出 importance 高于阈值(默认 0.6)的条目 → 将条目内容与已有 SemanticMemory 做语义匹配(判断是否存在相似度高于 0.85 的已有条目)→ 对匹配到的条目执行合并(追加引用计数并更新时间戳),对未匹配的条目新建 SemanticMemory 条目 → 从 WorkingMemory 中移除已整合的条目。consolidate 可手动触发或按固定周期(如每 10 轮交互)自动执行。
- summary / stats / update / remove / clear_all:其他管理操作
RAG 系统#
文档处理与 Chunk 策略#
任意格式文档(PDF、Word、Markdown、HTML 等)→ MarkItDown 工具统一转换为 Markdown 格式 → 解析标题层次(构建文档结构树)→ 段落语义分割(以自然段落为单位,保持语义完整性)→ Token 长度控制与 Chunk Overlap → 嵌入向量化 → 写入向量数据库(按命名空间隔离不同文档集)。
Chunk 策略选择直接影响 RAG 的检索质量。四种主流策略:
| 策略 | 说明 | 召回率 | 适用场景 |
|---|---|---|---|
| 固定大小切分 | 按固定 token 数切分(如 512 token),简单粗暴 | 约 67% | 粗略原型、文档结构不明确 |
| 基于结构切分 | 利用 HTML/Markdown 标题层级做切分点 | 约 74% | 有清晰标题结构的文档 |
| 递归切分 | 按分隔符层级(段落→句子→词)迭代分割 | 约 80% | 通用场景,兼顾粒度与语义 |
| 语义切分 | 用 Embedding 相似度检测语义边界,语义突变处分割 | 约 91% | 高质量需求、知识库型系统 |
Parent-Child Chunk 模式:小块(约 300 token)负责召回,大块(约 1200 token)负责生成。检索时命中小块,但将对应父段落放入 LLM 上下文中。小块提高了检索精确度,大块保证了生成时上下文完整。
检索结果重排序(Re-ranking)#
向量检索的第一轮结果(Top-30 到 Top-100)中,排名靠前的结果不一定最相关。重排序的目的:用更精确的模型对初筛结果二次排序。
三种重排序方法:
- Cross-Encoder Reranker:将 query 与每个候选文档拼接后送入一个专门的排序模型(如 BGE-Reranker、Cohere Rerank),输出相关性分数。比向量检索(Bi-Encoder)更精确,但需要逐对计算、延迟更高。
- LLM Rerank:利用 LLM 对候选文档进行排序,可解释性强(LLM 可以给出排序理由),但计算成本最高。
- 规则重排:按时间近因性、来源权威性、权限级别等元数据规则做排序,不依赖模型。
推荐检索链路:元数据预过滤 → 多路召回(向量 + 关键词,粗召回 30–100 条)→ 去重合并 → Cross-Encoder Rerank 选出 5–10 条 → 上下文压缩 → 送入 LLM。
高级检索策略#
MQE(Multi-Query Expansion,多查询扩展):
将用户的原始问题用 LLM 扩展成多个语义等价但表达不同的子问题(如”什么是 RAG”扩展为”RAG 的定义是什么""检索增强生成如何工作""RAG 和微调有什么区别”),每个子问题独立执行向量检索,合并所有检索结果去重后返回。MQE 提高了对模糊问题的召回率——同一个问题有多个表达方式,总有一种能匹配到文档中的相关表述。
HyDE(Hypothetical Document Embeddings,假想文档嵌入):
先让 LLM 根据用户问题生成一段”假想答案”(不需要十分准确,只需要在词汇和风格上接近目标文档),用这段假想答案的嵌入向量去检索目标文档。HyDE 利用了嵌入空间的”文本形态相似性”——问题和文档往往写法不同(问题短而口语化、文档长篇且专业),但两段假想答案和实际文档在词语层面更接近。适用于用户提问方式与知识库文档写法差异较大的场景。
Memory 与 RAG 的关系#
RAG 负责找知识,Memory 负责记历程。RAG 回答当前问题(从外部知识库检索事实性信息),Memory 支撑长期个性化(记住用户的偏好、行为模式和历史交互)。RAG 的知识源可以独立更新(替换知识库即可),Memory 的内容随交互持续积累(每次交互都是增量写入)。
典型协作模式:
- 加载新资料时:RAG 存文档 + Memory 记录”用户加载了什么资料”这一事件
- 提问回答时:RAG 检索资料生成答案 + Memory 记录问题和获得答案的学习轨迹
- 复盘学习时:Memory 回顾历史问题和笔记 + RAG 补充知识细节
- 制定计划时:RAG 提供领域知识 + Memory 提供用户进度和偏好
上下文工程#
系统提示(System Prompt)设计原则#
系统提示是上下文中优先级最高的固定部分,其设计质量直接影响 Agent 的行为边界和应对复杂场景的能力。以下几点是实践中需要关注的:
- 明确角色定位:定义 Agent 的身份、任务范围和限制条件。例如”你是代码审查助手,专注于 Python 后端代码”。角色定义帮助模型在任务边界内推理,减少”越界”行为。
- 工具描述标准化:每个工具的名称、功能、参数、适用场景和不适用场景都需要在系统提示中明确定义。工具描述的质量决定 Agent 能否在正确场景下选择正确的工具。
- 行为约束先于功能描述:先说”禁止做什么”再说”可以做什么”。安全约束(如”不允许执行
rm命令”)放在功能描述之前,优先级更高。 - 动态注入 vs 静态固化:固定信息(角色、规则、安全约束)写在系统提示中并长期不变;运行时信息(任务描述、工具列表)由 ContextBuilder 动态拼装。不将动态信息固化在系统提示中。
- 保持精简:系统提示并非越长越好。超出必要长度的系统提示会被模型同等对待为”需要关注的上下文”,稀释对实际任务信息的关注力。核心规则应该在 500 token 以内覆盖完毕。
上下文工程 vs 提示工程#
提示工程关注”怎么写好 prompt”,其核心问题是单轮或短任务内的指令优化。上下文工程则关注一个更广泛的问题:每一次调用模型前,应该把哪些信息、以什么结构、在多大预算内交给模型。需要考虑的对象包括系统提示(固定身份和行为规则)、工具描述(可用工具的 schema 和调用说明)、对话历史(过去的交互记录)、记忆(从长期记忆中召回的相关片段)、RAG 结果(从外部知识库检索的信息)、NoteTool 输出(结构化笔记)、TerminalTool 输出(文件系统探索结果)、Agent 状态(规划进度和未完成任务)。
上下文腐蚀(Context Rot)#
随着上下文窗口中 token 数量增加,模型从中准确回忆和使用关键信息的能力下降。原因有三:
- 注意力被拉薄:Transformer 的自注意力需要计算所有 token 两两之间的关联。当 token 数越多,模型在每一个 token 上的注意力权重越分散,关键信息被稀释。
- 噪声增多:无关的历史记录、重复的工具输出、过期的中间计划占据了有效的上下文空间,使模型难以抓住真正重要的信息。
- 训练分布限制:模型在预训练阶段接触的文本绝大多数在几千 token 以内,对超长序列中的信息提取经验不足。
GSSC 流水线#
ContextBuilder 的核心框架包含四个阶段:
第一阶段:Gather(汇集)#
从多个来源收集候选信息,包括:
- 系统指令:最高优先级,通常固定不变
- MemoryTool:从长期记忆中检索的相关记忆条目
- RAGTool:从外部知识库检索的知识片段
- 对话历史:仅保留最近 N 条记录(默认 N=20,可配置)
- 自定义信息包:NoteTool 的结构化笔记、TerminalTool 的输出等
第二阶段:Select(选择)#
采用加权评分机制对候选信息进行筛选:
combined_score = relevance_weight × relevance_score + recency_weight × recency_score流程:先分离系统指令(始终保留)→ 为每个候选信息计算综合分数 → 过滤低于 min_relevance 阈值的信息 → 按综合分数排序 → 贪心填充(从高分到低分逐个加入,直到 token 上限)。
超出上限的信息不会丢弃而是保留到下一轮。下一轮 Gather 仍会考虑它们,随时间衰减的 recency_score 可能使它们再次被选中。
第三阶段:Structure(结构化)#
将选中的信息组织为结构化的模板:
[Role & Policies] ← 系统指令(身份和规则)
[Task] ← 当前任务描述
[Evidence] ← RAG 检索结果、记忆片段
[Context] ← 对话历史摘要或近期记录
[Output] ← 输出格式要求和示例固定模板的意义在于:让模型每次看到的上下文信息在同一个位置出现,模型学会从固定位置寻找特定类型的信息。如果每次信息排列方式都不同,模型需要在推理时额外花费 attention 来定位信息。
第四阶段:Compress(压缩)#
当所有候选信息即使经过选择仍超出上下文窗口时,对已构成但超限的上下文进行兜底压缩。压缩规则:优先压缩重复度高的信息(如多个相似文档片段只保留一个)、其次压缩时间较早且评分低的信息、最后压缩辅助性信息(如工具使用示例)。保留优先级:关键决策 > 未解决问题 > 约束条件 > 下一步行动 > 背景信息。
NoteTool(结构化笔记)#
面向长时程任务的结构化外部记忆。Agent 在执行过程中可以主动写入笔记,笔记内容持久化到本地文件,在后续交互中由 ContextBuilder 检索加载。
格式为 Markdown + YAML 前置元数据。分类体系:
- blocker:当前卡点或阻塞项(如”xxx 模块需要 xxx 库,但当前环境未安装”)
- action:已执行或待执行的操作(如”已修改 xxx 文件,待验证”)
- task_state:任务进度状态(如”Phase 1 完成 80%,剩下 xxx 子任务”)
- conclusion:已形成的结论(如”确定了该项目的前后端分离方案”)
- reference:参考信息(如”xxx API 的文档链接""xxx 配置文件路径”)
- scratch:临时草稿和中间结果
TerminalTool(即时文件系统访问)#
实现 JIT(Just-in-Time)上下文——在需要时才去探索文件系统,而不是把所有文件内容预先加载到上下文中。
安全机制:
- 命令白名单:仅允许指定的命令(如
ls、cat、find、grep)执行,禁止rm、sudo等危险命令 - 工作目录沙箱:限定命令只能在指定的根目录下执行,禁止
..越级访问 - 超时控制:命令执行超过指定时限时自动终止
- 输出大小限制:命令输出的内容超过指定 token 数时自动截断
适用场景:日志分析(按需搜索特定模式)、代码库探索(查找文件、搜索定义)、数据文件分析(预览文件结构)。
长时程任务三大策略#
| 策略 | 解决的问题 | 典型做法 | 适用场景 |
|---|---|---|---|
| Compaction | 对话历史过长,窗口接近上限 | 用 LLM 高保真总结历史后重启上下文 | 长时间连续对话、持续研究 |
| Structured Note-taking | 关键状态需跨窗口持续保存 | 将结论 / 阻塞 / 计划写入 NoteTool | 多天项目维护、复杂计划 |
| Sub-agent | 单一上下文无法容纳多方向并行探索 | 主 Agent 规划,子 Agent 独立探索后回传摘要 | 大规模代码库分析、多方排查 |
上下文工程的系统层级#
上下文管理并非单一工具能解决的问题,需要在多个抽象层级上协同:TerminalTool 工作在”即时访问层”(当前轮按需加载)→ MemoryTool 工作在”会话记忆层”(会话内到跨会话)→ NoteTool 工作在”持久笔记层”(跨天跨会话)→ ContextBuilder 工作在”上下文编排层”(每次模型调用前的信息汇总)。
实践原则#
- 上下文不是越多越好,而是越相关、越新、越结构化越好
- 系统提示要稳定,但不能把复杂业务流程全部硬塞进提示
- 工具集要小而清晰,职责单一、边界清楚
- 长程任务必须有外部状态层,不能只依赖对话历史
- JIT 上下文(TerminalTool)适合动态信息,RAG 适合稳定、语义化、可复用的知识
- 压缩要保留决策、约束、未解决问题和下一步
- 笔记必须定期整理(consolidate),否则会从”外部记忆”变成”外部噪声”
- 高风险工具调用必须有安全边界和人类审批
Agent Skills#
Agent Skills 规范由 Anthropic 提出,定义了如何将能力打包为可以被 Agent 发现和使用的方式。
渐进式披露(Progressive Disclosure)#
将技能信息分为三层,避免一次性将所有内容塞入上下文窗口:
- 元数据层:约 100 tokens 每技能,包含技能名称、一句话描述、关键标签。当 Agent 需要选择技能时,仅加载元数据层即可进行初步筛选。
- 技能主体:技能的核心信息——具体能做什么、需要什么工具、输入输出格式。当 Agent 确认使用某个技能时再加载这一层。
- 附加资源:示例代码、FAQ、详细文档。仅在 Agent 需要深入学习或在运行时遇到困难时加载。
这种设计使 Agent 能在有限的上下文空间中同时了解多种可用能力,仅在需要时深入某个技能的细节。
SKILL.md 规范#
每个技能的描述文件,定义了以下关键字段:name(技能名称)、description(技能作用描述)、version(版本号)、allowed_tools(技能允许使用的工具列表)、workflow(工作流程说明)、best_practices(最佳实践和使用注意事项)。
Agent Skills 与 MCP 的关系#
MCP 解决”连接性”问题——让智能体能够访问外部工具和数据。Agent Skills 解决”能力”问题——告诉智能体如何正确使用这些工具以达到某个目标。MCP 定义了通信的底层协议(如何传输工具调用和返回),Agent Skills 定义了上层使用方法(在什么场景下应该调用哪些工具、按什么顺序调用)。
Agent通信协议#
MCP(Model Context Protocol)#
Anthropic 提出的开放协议,旨在标准化 LLM 应用程序与外部工具和数据源的交互方式。MCP 解决的是连接性问题——让智能体能够访问外部工具和数据。
三层架构:
- Host(宿主层):需要与外部系统交互的 LLM 应用,如 Claude Desktop、IDE 插件
- Client(客户端层):Host 内部与 MCP Server 建立连接的组件,负责管理连接生命周期
- Server(服务器层):暴露特定能力的轻量级服务,每个 Server 负责一个功能域(文件系统、数据库、外部 API)
三大核心能力:
- Tools:可主动调用的功能,如搜索、计算、API 请求。需要 Host 授权才能执行。
- Resources:可被读取的数据源,如文件内容、数据库记录、API 返回结果。类似 REST API 的 GET 请求。Resources 支持两种获取方式:直接读取(Host 按 URI 请求资源内容,一次性获取完整数据)和订阅模式(Host 向 Server 订阅资源变更通知,当资源内容变化时 Server 主动推送更新,无需 Host 轮询)。Resources 还支持 Resource Template——用 URI 模板(如
file://{path})定义一类资源的模式,Host 在运行时填充模板参数后即可获取具体资源。 - Prompts:预定义的 prompt 模板,指导 LLM 如何与特定资源或工具交互。
传输方式:
- stdio:MCP Server 与 Host 在同一进程,通过标准输入输出通信,适合嵌入式和本地部署
- SSE(Server-Sent Events):HTTP 长连接,Host 与 Server 分离,适合远程部署
- Streamable HTTP:Anthropic 引入的流式 HTTP 传输方案。相比 SSE 的改进:统一了连接生命周期管理(支持长连接和按需短连接的自动切换)、内置心跳和重连机制(客户端断连后自动恢复)、支持双向流(Server 可以向 Host 推送更新,Host 也可以主动向 Server 发送请求)。仅在需要时建立连接,空闲时自动关闭。
与 Function Calling 的关系:互补而非竞争。Function Calling 是 LLM 模型的一种能力——从模型输出中识别需要调用工具的意图并生成结构化参数。MCP 是基础设施协议——统一了工具的注册、发现、调用方式。Function Calling 决定”是否需要调用工具”,MCP 决定”如何找到并调用工具”。
A2A(Agent-to-Agent Protocol)#
Google 提出的点对点 Agent 协作协议,解决的是不同 Agent 系统之间的互操作问题。每个 Agent 既是服务提供者也是服务消费者。
核心组件:
- Agent Card:Agent 的能力声明文件,JSON 格式,描述 Agent 的身份、支持的技能、接口端点。示例:
{
"name": "research-assistant",
"description": "Deep research agent for academic papers",
"skills": ["paper_search", "summary_generation", "citation_analysis"],
"endpoints": {
"base_url": "http://localhost:8080",
"tasks": "/tasks",
"stream": "/tasks/stream"
},
"auth": { "type": "api_key", "header": "X-API-Key" }
}- Task:任务的生命周期管理,包括任务的提交、状态跟踪、取消
- Message:Agent 间的通信消息实体
- Part:消息中的内容单元,可以是一段文本、一个文件引用、一个结构化数据块
A2A 的优势:避免中心化协调器瓶颈(去除了单点故障和性能瓶颈)、天然支持流式与事件驱动通信(Agent 可以实时推送进度而非轮询)。
ANP(Agent Network Protocol)#
开源社区提出的概念性协议框架,定位于大规模智能体网络的去中心化服务发现。类似微服务架构中的服务注册中心(Consul / Etcd),但 AGent 可以主动声明和撤销自己的能力注册,其他 Agent 通过查询网络发现可用的服务。
ANP 在当前阶段生态尚不成熟,课程中作为概念性了解。
协议定位对比#
三种协议在 Agent 生态中处于不同层次:
- MCP 负责”接入外部能力”(LLM ↔ 工具 / 数据源),解决的是垂直集成问题
- A2A 负责”多 Agent 编排”(Agent ↔ Agent),解决的是水平协作问题
- ANP 负责”大规模服务发现”(Agent ↔ 网络),解决的是组织管理问题
三者可以共存和互补。一个典型的多 Agent 系统中:ANP 帮助 Agent 发现其他 Agent 和能力 → A2A 在发现后进行对等通信协作 → MCP 让每个 Agent 接入自己的工具和数据。
Agentic-RL#
从 LLM 训练到 Agentic RL#
核心思想是将 LLM 作为可学习策略,嵌入智能体的感知-决策-执行循环中,通过强化学习优化多步任务表现。传统的 Agent 构建方式依赖 prompt 工程——Agent 的行为完全由系统提示词固定,无法针对特定任务环境进行优化。Agentic RL 则允许 Agent 通过与环境交互的奖励信号来学习最优行为策略。
Agentic RL 与传统 PBRFT(即 RLHF / PPO 用于文本偏好优化)的关键差异:
| 维度 | 传统 PBRFT | Agentic RL |
|---|---|---|
| 状态空间 | 静态 prompt + 单轮回复 | 多轮交互过程中动态演化的上下文 |
| 行动空间 | 仅文本生成 | 文本生成 + 工具调用参数生成 + 环境操作 |
| 奖励设计 | 人类偏好评分(单次输出质量) | 任务完成度累积奖励(多步序列决策效果) |
| 时间跨度 | T=1(单步) | T≫1(多步序列) |
GSM8K 数据集#
GSM8K 是小学数学应用题数据集,包含 7,473 个训练样本和 1,319 个测试样本。题目涉及加减乘除、比例、单位换算等基础数学运算,多为两步以上推理。
在课程中的使用方式:
- SFT 格式:提供完整的问题和逐步解题过程,作为监督信号
- RL 格式:仅提供问题文本和最终正确答案(只给一个数字),不提供解题过程
RL 格式的设计意图:迫使模型通过自身的探索来发现正确的推理路径,而非模仿现成的解题过程。这更能反映 Agent 在真实环境中面对的”有目标无路径”的问题。
奖励函数#
三种奖励函数设计,各具不同的优化目标:
- AccuracyReward:答案正确时奖励 +1,错误时奖励 0。这是最直接的奖励信号,但只关注最终结果的正确性,不关心推理过程的质量。
- LengthPenaltyReward:仅当答案正确时,对过长的回答施加惩罚。解决 Agent”为了安全而冗余”的问题——如果一个 Agent 用了 500 token 的推理得到了正确答案,而另一个只用了 100 token,后者获得更高的奖励。
- StepReward:奖励清晰的推理步骤。鼓励模型将推理过程分解为明确的逻辑步骤,而不是长成一整段。步骤越清晰、每一步的推理越合理,奖励越高。
在实际训练中,三种奖励函数通常加权组合:total_reward = w1 × AccuracyReward + w2 × LengthPenaltyReward + w3 × StepReward。
SFT 监督微调#
SFT 阶段的目标是”教会模型如何回答”——输出格式、推理模式、使用工具的规范。使用 LoRA 参数高效微调(Qwen3-0.6B + LoRA 仅需约 4GB 显存)。
SFT 的作用:
- 建立基线行为:模型学会至少为每个问题生成”看起来合理”的推理轨迹
- 学习输出格式:模型学会在文本中嵌入推理步骤、工具调用、最终答案的结构
- 避免 RL 训练初期随机探索的低效:有 SFT 基线之后,RL 可以在”基本可用”的基础上做优化,而不是从零开始探索
GRPO 群组相对策略优化#
与传统 PPO 相比,GRPO 的核心创新是使用组内相对奖励替代 PPO 的优势函数——不需要训练一个独立的 Value Model(价值网络,用来估计状态价值的神经网络),简化了训练流程。
训练流程:
- 对同一个输入问题,当前策略模型生成 N 个不同的答案(即一个”群组”,N 通常为 4–8)
- 使用奖励函数计算每个答案的奖励分数
- 计算群组内奖励的平均值
- 对每个答案,计算”相对优势” = 该答案的奖励 - 群组平均奖励
- 用相对优势作为信号更新策略模型——相对优势为正的答案对应的生成路径被强化,相对优势为负的路径被抑制
GRPO 的设计直觉:不需要一个绝对的价值判断(“这个答案值多少分”),只需要相对比较(“这个答案在这个群组里是更好还是更差”)。相对比较对奖励函数的尺度不敏感,训练更稳定。
技术栈#
| 层级 | 组件 |
|---|---|
| 数据集层 | GSM8KDataset, create_sft_dataset(), create_rl_dataset() |
| 奖励函数层 | AccuracyReward, LengthPenaltyReward, StepReward |
| 训练器层 | SFTTrainerWrapper, GRPOTrainerWrapper |
| 统一接口层 | RLTrainingTool |
技术选型方案为 HuggingFace TRL(Transformer Reinforcement Learning,HuggingFace 官方提供的强化学习训练工具库)+ Qwen3-0.6B 模型。
快速上手#
from hello_agents.tools import RLTrainingTool
rl_tool = RLTrainingTool()
# SFT 训练
rl_tool.run({
"action": "train",
"algorithm": "sft",
"model_name": "Qwen/Qwen3-0.6B",
"output_dir": "./models/quick_sft",
"use_lora": True
})
# GRPO 训练
rl_tool.run({
"action": "train",
"algorithm": "grpo",
"model_name": "Qwen/Qwen3-0.6B",
"output_dir": "./models/quick_grpo",
"num_generations": 4, # 每个问题生成 4 个答案
"use_lora": True
})性能评估#
评估目标#
智能体评估的四个目标:
- 量化性能:知道系统当前达到了什么水平,是”完全可以用”还是”仅能用于 demo”
- 对比方案:在不同 Agent 方案、不同模型、不同 prompt 版本之间做出客观选择
- 发现弱点:定位系统瓶颈和改进方向——是工具调用选择不正确?记忆检索不准?还是推理能力不足?
- 证明可靠性:在发布到生产环境之前,确保系统在各类场景下行为正确
BFCL(Berkeley Function Calling Leaderboard)#
伯克利大学提出的评估智能体工具调用能力的基准。使用 AST 匹配算法评估函数调用是否与期望调用完全一致(包括函数名、参数名、参数值类型、嵌套结构)。
四个评估类别:
- Simple:单个函数调用,参数直接匹配
- Multiple:需要依次调用多个独立函数,每个调用的输出可能是下一个的输入
- Parallel:多个函数调用之间没有依赖关系,可以并行执行,需要模型在一次回复中同时产生多个工具调用
- Irrelevance:测试模型判断”何时不需要调用工具”的能力——某些问题不需要调用任何工具即可回答,模型如果过度调用工具会被扣分
三种使用方式:
- BFCLEvaluationTool(推荐):一行代码完成评估
- 一键评估脚本:
04_run_bfcl_evaluation.py --category simple --samples 10 - 直接使用 Dataset + Evaluator:自定义评估流程,适用于需要修改评估逻辑的场景
GAIA(General AI Assistants)#
通用 AI 助手的综合能力评估基准,包含 466 个任务。GAIA 的设计理念:一个好的 AI 助手应该在完成端到端任务时表现出色,而不仅仅是回答事实性问题。任务要求 Agent 自主规划、搜索、推理、组合多源信息。
四级基准:
| 层级 | 能力要求 | 典型任务 |
|---|---|---|
| 基础层 | 文档解析、简单推理 | 从 PDF 中提取关键数据并计算 |
| 进阶层 | 多模态交互、资源整合 | 分析 PPT 内容并生成邮件,整合网络资源完成调研 |
| 专家层 | 跨领域知识迁移 | 结合医疗知识和法律文书审核 |
| 挑战层 | 动态环境适应 | 根据实时数据调整策略 |
数据:仅有约 8.7% 的开源 Agent 能通过全部专家层测试。主要瓶颈包括:长上下文记忆能力不足、跨模态语义对齐误差、异常处理策略缺失。
数据生成质量评估#
针对 Agent 系统的输出(如生成的报告、翻译、摘要),除客观指标外还需要质量评估。主要方法:
- LLM-as-Judge:用另一个更强的 LLM 作为评价者,对 Agent 的输出按多个维度打分。典型 prompt 模板:
你是一位严格的评审者。请从以下几个维度对以下回答进行评分(1-5分):
1. 准确性:回答中的事实是否都有依据?
2. 完整性:回答是否覆盖了问题的所有方面?
3. 相关性:回答的内容与问题是否直接相关?
4. 可读性:回答是否清晰、结构化?
问题:{question}
Agent的回答:{answer}
请以JSON格式输出评分和理由。- Win Rate:将 Agent A 与 Agent B(如基线方案)的输出对比,计算人类或 LLM 评价者更偏好 A 的百分比
Agent 安全风险#
提示注入(Prompt Injection)#
提示注入是最常见的 Agent 安全问题。攻击者通过在用户输入中嵌入恶意指令,让 Agent 忽略原始系统提示并执行攻击者的意图。分为直接注入(用户输入直接包含恶意指令)和间接注入(恶意指令通过 Agent 检索到的外部文档内容传入)。
缓解策略:将用户输入与系统指令在上下文中用明确的边界标记隔离;对 Agent 可以执行的工具有严格的权限控制;对于高风险操作(文件删除、数据修改、支付)设置人工确认环节。
工具滥用与权限逃逸#
Agent 自主调用工具的能力如果缺乏限制,可能导致:工具被调用来执行其设计范围之外的操作(如搜索工具被用来构建隐私信息);Agent 利用了权限提升获取本不该访问的数据;工具调用的参数超出安全范围(如文件读取工具被传入 ../../../etc/passwd)。
缓解策略:每个工具定义明确的参数范围约束;工具执行器的命令白名单、路径沙箱、超时控制;工具调用按风险等级分级(低风险自动执行、中风险记录日志、高风险人工确认)。
数据泄露#
Agent 在执行过程中可能将敏感数据(API Key、用户隐私、内部文档)作为上下文的一部分传递给外部 LLM。另一方面,Agent 也可能从外部工具获取数据后错误地暴露给未授权的用户。
缓解策略:在输入上下文中自动检测和脱敏敏感信息;对 Agent 的输出进行后处理过滤;工具的执行环境隔离(TerminalTool 的工作目录沙箱)。
输出安全#
Agent 的输出可能包含虚构信息(幻觉)、误导性内容、或未经核实的断言。当 Agent 具备工具调用能力时,输出的安全边界比纯文本 LLM 更广——Agent 可能调用工具执行了操作然后告诉用户”已执行”,但实际上并未执行(或执行了不同的操作)。
缓解策略:工具调用的执行结果必须如实反馈给用户;对于影响外部系统的操作,提供操作确认步骤;使用 Reflection 范式让 Agent 在执行完整操作前自我检查。